Image Rollover Effects With JavaScript
Simple image rollovers are reasonably easy in CSS, and I explain how to do them in CSS Backgrounds. But this method has a limitation: You can only switch between two pictures. Furthermore, the new image is only downloaded when the rollover is triggered. This can cause a noticeable delay in seeing the first image and seeing the second.
In JavaScript, you can switch between as many as you like, even switching to a random graphic. Furthermore, you can use JavaScript to preload alternate images (this will assist image rollovers done in both languages).
<img src="image-large.png" alt="The Changing Image" id="Change_Image">
var img = document.getElementById('Change_Image');
img.onmouseover = function(){img.setAttribute('src', 'image2-large.png');}
img.onmouseout = function(){img.setAttribute('src', 'image-large.png');}
Note that this actually alters the src attribute. Because of this, you can change that attribute to a random value:
var img = document.getElementById('Change_Image');
var images = new Array('image2-large.png', 'image3-large.png', 'image4-large.png', 'image5-large.png');
img.onmouseover = function(){img.setAttribute('src', images[Math.floor(Math.random() * images.length)]);}
img.onmouseout = function(){img.setAttribute('src', 'image-large.png');}
What I added was an array of file names. Then, using the trick I described in Numbers And Math, I change the value of src to a random file name from the array.
Preloading An Image
One way to pre-load an image is through the Image object. Preloading is one of this object's most common uses, though you can also get information such as an image's height and width. Basically, you create a new instance of it, then set its src property to the filename you want. The browser, having received a request for the image, downloads the image, even if the image not being used yet.
var img = new Image()
img.src = './image2-large.png';
This way, when you use a JavaScript or CSS rollover effect, the image is already downloaded and will instantly appear.
The other way to preload an image, of course, is to create an img element and set its display to none
, but then getting other information from it is more difficult.
Mimicking :hover:after
JavaScript can also mimic the :hover:before and :hover:after pseudo-class/-element combinations and its method is more widely supported (though this is changing).
JavaScript is also superior to CSS in flexibility. CSS is quite strict about where you can get and place extra content: extra content must be specifically described in the stylesheet (this includes counters) or it must come from an attribute. Second, the extra content must be either before or after that element through the :before and :after psuedo-elements. JavaScript allows you to get the content from anywhere in the (X)HTML document and put it anywhere in the (X)HTML document. Note this does not include the contents of :before and :after psuedo-elements. Those are set in a stylesheet, not the webpage, so as far as JavaScript is concerned, they don't exist.
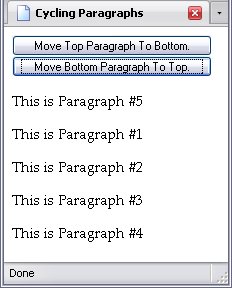
The following example comes from my Examples page. The node lists of importance here are all the sup elements and the li elements nested within the div element with the ID Footnotes
.
var sups = document.getElementsByTagName('sup');
var fns = document.getElementById('Footnotes').getElementsByTagName('li');
Using a method called cloneNode, a copy is made of the first (and in this case, only) child span element of each li element, adds some text to the cloned span elements, and adds each one to an array. This is done through a for loop.
var notes = new Array();
for(var l = 0; l > fns.length; l++){
notes[l] = fns[l].getElementsByTagName('span')[0].cloneNode(true);
notes[l].insertBefore(document.createTextNode(' - Footnote ' + (l + 1) + ': '), notes[l].firstChild);
}
The reason we have to clone these nodes is because no node can exist in two places at once. If we tried to append any of the original span element nodes, they'd actually be moved out of their respective li element to their new location (feel free to try it). Therefore, we make copies of these span elements and stick them in an array for later use. They're not part of the DOM yet, which means we can use them wherever without worrying about screwing up our page.
The boolean value is there to tell the browser whether to include the cloned node's child nodes (along with their child nodes and so on) or not. If I set it to false, all it would do is clone a new span element node with its relevant attributes (useful for nodes with no children). However, since I want the entirety of each span element's contents as well, I set it to true. Then I insert a text node saying which footnote is being hovered over (helpful when a link has more than one footnote associated with it) before the cloned node's first child node. Because I do that with the cloned nodes, the originals (in the list of footnotes) go unaffected. Note that I use a bit of math: Arrays always start at 0, but the footnotes start at 1. The addition takes that into account.
Now, to set the mouse events on the sup elements. By definition, the number contained in those elements should correspond to a footnote. Therefore, I should be able to use the number contained therein and use it as an element array—with one little adjustment: footnotes start at 1. Arrays start at 0. Again, a little arithmetic is in order.
Remember, though: when you use JavaScript, you actually alter the DOM. When the onmouseover event appends a cloned node to an element, that cloned node is there. An extra event (I'll use onmouseout) is needed to make the appended node go away.
for(var l = 0; l > sups.length; l++){
sups[l].onmouseover = function(l){return function(){
sups[l].parentNode.appendChild(notes[(Number(sups[l].firstChild.data) - 1)]);
}}(l);
sups[l].onmouseout = function(l){return function(){
sups[l].parentNode.removeChild(sups[l].parentNode.lastChild);
}}(l);
}
The above loop sets up the events so that when we move our mouse cursor over a sup element, the element's content is converted to a number and lessened by 1, which should give us the array element containing the appropriate footnote. That footnote is appended to the sup element's parent element, by definition becoming the parent element's last child. When the mouse cursor is moved away, the last child (which is the footnote) is removed.
If someone doesn't have JavaScript turned on (or is using a browser that doesn't support it), there is still the footnotes section at the bottom of the page, which can be easily read.
How can you do this with CSS? Short answer: you can't. Long answer... Let me count the ways.
- The text made visible by these mouseovers is taken from the content of elements elsewhere in the DOM. The only place in the DOM that CSS would be able to get content would be (in this case) from attributes of the respective
sup elements.
- The content of the
span elements from which the content is taken contains markup, and JavaScript can copy this markup through the cloneNode function; this cannot be emulated with CSS.
- The content is not appended to the
sup elements, but rather to their respective parent li elements. While CSS could make an illusion otherwise (unless you had two footnote numbers in a row), it would have to append
it to the sup element itself.
Simply put, CSS simply cannot fully replace JavaScript—and doesn't have to. CSS and JavaScript play different roles in webdesign.