Regular Expressions
The first thing you need to know about regular expressions is regular expressions are not text. Instead, a regular expression (regex for short) is a pattern of text. Below are two possible patterns:
- #-###-###-####
- @#@ #@#
In the above patterns, #
stands for any number from 0 through 9, and @
stands for any letter from A through Z. What do these patterns represent? Pattern #1 represents a Canadian phone number, #2 a Canadian postal code. (By the way, I'm Canadian. Could you tell?) More importantly, these patterns could match any phone number or postal code, not just a specific one. While regexes can be used to match exact text, that's not really their function.
Regular Expression Terms
- Regular Expression
- A means of describing a pattern of text to match, rather than a specific piece of text.
- Literal
- Text that is to be matched exactly.
- Metacharacter
- A character that is given special meaning in a regex.
- Escape sequence
- This allows metacharacters to be treated as literals and certain literals to be treated as metacharacters.
Creating A Regular Expression
Instead of quotation marks, regular expressions begin and end with forward slashes (/
)
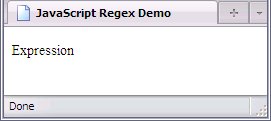
var regex = /Expression/;
var regex = new RegExp("Expression");
The above will match a pattern in some text; the pattern matched is the word Expression
, capitalized precisely as described in the expression (regexes, just like everything else in JavaScript, are case-sensitive).
The advantage to creating a regex through the RegExp object is that this particular means allows a regex to be generated from variables, which can't be done by simply concatenating expressions like you do strings.
Using Regular Expressions
Regular Expressions can be used with the following string methods:
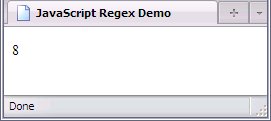
There's another method that can be used: test, which returns true
or false
. This is a method associated with regexes, not strings. So I'm going to use two variables here: string, which holds the string "Regular Expression", and regex, which holds the regular expression /Expression/ (this is an example of a literal), and demonstrate these methods.
- string.
match(regex);
- If there is one or more substrings in string that matches the pattern of regex, the first such substring will be returned, otherwise a null value will be returned.
- string.
search(regex);
- If there is one or more substrings in string that matches the pattern of regex, the position of the first such substring will be returned; if not, then a value of -1 will be returned.
- string.
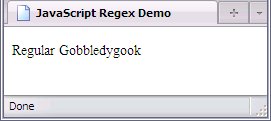
replace(regex, "Gobbledygook");
- If there is one or more substrings in string that matches the pattern of regex, a string with the first such substring replaced will be returned.
- regex.
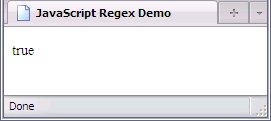
test(string);
- If there is one or more substrings in string that matches the pattern of regex, the boolean value
true
will be returned. Note where the variables regex and string are!
So far, we haven't done anything with a regex that we can't do with a string, but at least we know how to use them. So now, I'm going to demonstrate more complex expressions.
Checking Against Two Different Patterns
The vertical bar (|
) is a metacharacter in regexes that allows you to check against patterns on either side of it. For example, if you had the regex /regular|expression/, it would check to see if the tested string contained either the word regular
, expression
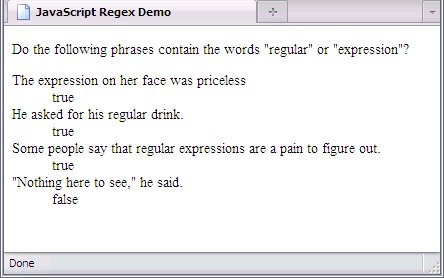
, or both. Below is a script that does precisely that:
var dts = document.getElementsByTagName('dt');
var dds = document.getElementsByTagName('dd');
var exp = /regular|expression/;
dds[0].firstChild.data = exp.test(dts[0].firstChild.data);
dds[1].firstChild.data = exp.test(dts[1].firstChild.data);
dds[2].firstChild.data = exp.test(dts[2].firstChild.data);
dds[3].firstChild.data = exp.test(dts[3].firstChild.data);
The phrases this script was used on and the results are shown below:
Discounting the paragraph at the beginning, the first phrase has the word expression
, the second has the word regular
and the third has both (since the word expressions
does match the second literal), so all these test true
. The fourth has neither word, so it tests false
.
On a final note, you're not limited to two choices. Using extra vertical bars, you can have as many options as you need.
Groups Of Characters
A regex can also check to see if one of a group of characters is in it. For example, if you tried to test for expression, but a certain string contained Expression
instead, there would be no match; remember, regular expressions are case sensitive,
One thing you can do is check for both the upper- and lower-case e
, then the rest of the word—but first, you have to group those two characters together so that they're treated as options for one character. The two meta characters to do that are:
- [
- This begins a group of characters
- ]
- This ends a group of characters.
So to check for either a lower- or upper-case E
, you would group them together like this: [Ee]. Switching the order ([eE]) would work just as well. >A regex consisting of only [Ee] would match almost any sentence in the English language. In fact, it is uncommon for such a grammatical unit to not match; this particular string of words is an illustration of that, and as such was hard to write.
... wait. Drat.
Moving on.
What I can do in this instance is immediately follow the group of characters with the rest of the word (which is a literal), resulting in the regex [Ee]xpression. This is how this regex works:
- [Ee]
- The first character is either
E
or e
.
- xpression
- The next 9 characters are
xpression
in that order, with that case, and no spaces between them.
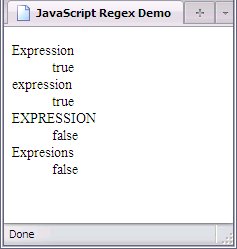
Let's see how that works (the script used for this page isalmost identical to that above save for the regex):
Note that while Expression
and expression
both match, EXPRESSION
and Expresions
do not; while the E
at the front of both words fits the pattern, XPRESSION
is all in upper-case when the the regex clearly specifies that those letters must be lower-case, and xpresions
has the letters out of order.
Character Ranges
Sometimes, you want a rather large group of characters that can be arranged into a sequence. For example, to test for a Canadian long-distance phone number (for example, if you're caling someone outside the province you're calling from, you're calling long-distance), the first thing we need to do is to test if each character is a number. We can do that with the group [1234567890]—which gets pretty tedious when the phone numbers comprise of 11 digits. To shorten things, we can use a hyphen (-
) to specify a range of characters, in this case 0 through 9: [0-9]. Note: a range must always be in ascending order. If you wrote the range as [9-0], the browser would see that as an error. When used outside brackets, the hyphen is a literal. So let's set up our regex.
- 1-
- The first number in a Canadian phone number (if you're dialing long-distance) is always
1
, and when it appears it print, it's usually followed by a hyphen (of course, you don't dial the hyphen).
- 1-[2-9][0-9][0-9]
- Following the
1-
is an area code. Now notice I specified the range [2-9] as the range. This is because that series of numbers never begins with 1
or 0
, so we omit those from the range.
- 1-[2-9][0-9][0-9]-[2-9][0-9][0-9]
- Following that, we enter the town number, which is another series of three digits that never begins with
1
or 0
.
- 1-[2-9][0-9][0-9]-[2-9][0-9][0-9]-[0-9][0-9][0-9][0-9]
- And here is our complete long-distance phone number.
This can be used with letters as well, although in this case, the ranges would be [A-Z] for capital letters and [a-z] for lower-case letters. For example, the regex [A-Z][0-9][A-Z] [0-9][A-Z][0-9] would match any Canadian postal code. I've created a script that will test various sentances to see if they contain a valid postal code.
var trs = document.getElementsByTagName('tr');
var exp = /[A-Z][0-9][A-Z] [0-9][A-Z][0-9]/;
trs[1].firstChild.nextSibling.firstChild.data = exp.test(trs[1].firstChild.firstChild.data);
trs[2].firstChild.nextSibling.firstChild.data = exp.test(trs[2].firstChild.firstChild.data);
trs[3].firstChild.nextSibling.firstChild.data = exp.test(trs[3].firstChild.firstChild.data);
trs[4].firstChild.nextSibling.firstChild.data = exp.test(trs[4].firstChild.firstChild.data);
Ranges and extra characters.
If you wanted to do a range of characters plus a few extra (for example, if you wanted to match hexadecimal), then you would simply add in the characters either before or after the group. You can even include two ranges. For example, matching hex characters could be either [0-9ABCDEF] or [0-9A-F]. If you wanted to account for the fact that some people use lower case when writing hexadecimal numbers, this would be [0-9A-Fa-f]. [A-Za-z] would refer to all letters, whether upper or lower case.
Excluding Characters
A bit of study on Canadian postal codes will reveal that the letters D, F, I, O, Q, and U are never used in a postal code. Z and W are, but not currently as the first letter. So the postal codes that can exist are a bit more limited. Using this knowledge, we can create another regex to narrow things down: this time, to exclude those characters.
When you want to match anything but a specific set of characters, you begin that set with a caret (^
). For example, matching anything but D, F, I, O, Q, or U would be [^DFIOQU]. However, this will match anything that is not D, F, I, O, Q, or U, which means that this, by itself, will not do. So we need to expand it a bit to a full postal code: /[^DFIOQUWZ][0-9][^DFIOQU] [0-9][^DFIOQU][0-9]/.
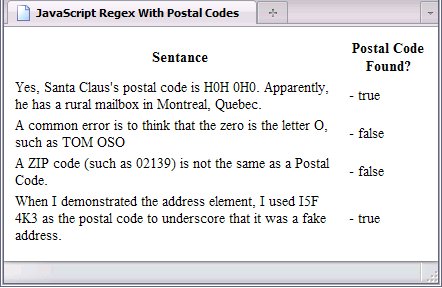
Adjusting the script, we can create a script that will filter our postal code matches even further. One way to do this is to use the match method to extract what looks like a postal code (using the first regular expression), and then use a second regular expression to check the matched text (if there is any).
var trs = document.getElementsByTagName('tr');
var exp = /[A-Z][0-9][A-Z] [0-9][A-Z][0-9]/;
var filt = /[^DFIOQUWZ][0-9][^DFIOQU] [0-9][^DFIOQU][0-9]/;
var code;
code = trs[1].firstChild.firstChild.data.match(exp);
trs[1].firstChild.nextSibling.firstChild.data = ' - ' + code;
trs[1].firstChild.nextSibling.nextSibling.firstChild.data = filt.test(code);
code = trs[2].firstChild.firstChild.data.match(exp);
trs[2].firstChild.nextSibling.firstChild.data = ' - ' + code;
trs[2].firstChild.nextSibling.nextSibling.firstChild.data = filt.test(code);
code = trs[3].firstChild.firstChild.data.match(exp);
trs[3].firstChild.nextSibling.firstChild.data = ' - ' + code;
trs[3].firstChild.nextSibling.nextSibling.firstChild.data = filt.test(code);
code = trs[4].firstChild.firstChild.data.match(exp);
trs[4].firstChild.nextSibling.firstChild.data = ' - ' + code;
trs[4].firstChild.nextSibling.nextSibling.firstChild.data = filt.test(code);
Note that this will not detect if a postal code actually does exist, only if it can. As the postal code I used to demonstrate the address element (I5F 4K3
) cannot exist—it uses both I
and F
—it works well for a fake address.
Oh, and yes, I do know I could have also written the regex as /[A-CEGHJ-NPR-TVXY][0-9][A-CEGHJ-NPR-TV-Z] [0-9][A-CEGHJ-NPR-TV-Z][0-9]/, but that would put a damper on this demonstration, wouldn't it?.
Special Characters In Regular Expressions
There are a number of other metacharacters in regular expressions, so I'll give them a quick rundown.
- .
- This will match any character except a newline character.
- ^
- This will match the beginning of a line (unless, of course, it's used in a character set; for example
[^DFIOQUWZ]
.)
- $
- This will match the end of a line.
- ?
- The preceding character may appear either once or not at all.
- *
- The preceding character may appear as often as you wish, from zero to as many times the text file allows.
- +
- The preceding character must appear at least once.
- \
-
This is the escape character, which I mentioned back in Text. It allows metacharacters to be treated as literals and certain literal characters to be treated as metacharacters. Aside from what was mentioned in Text, these are:
- \d
- Any decimal character. This is basically short for
[0-9]
- \D
- Any non-decimal character. This is basically short for
[^0-9]
- \s
- This matches whitespace (spaces, new lines, etc.)
- \S
- This matches everything but whitespace.
- \w
- This matches any letter, number, and underscore (short for
[0-9a-zA-Z_])
- \W
- This matches anything but letters, numbers, and underscores (short for
[^0-9a-zA-Z_]).
- \/
- \^
- \$
- \\
- The above are examples of the backslash causing metacharacters to be interpreted as literals. For example, the forward slash (
/
) normally begins and ends a regex, but in this case refers to an actual forward slash.
Subpatterns In Regular Expressions
A subpattern is a regular expression within a larger regular expression. A subpattern starts with (
and ends with )
. A subpattern must be able to stand on its own as a regular expression.
Here is an example that tests for displayed tags of elements related to tables: in short, occurances of <caption>
, <col>
, <colgroup>
, <table>
, <tbody>
, <tfoot>
, <thead>
, <td>
, <th>
, <tr>
, and their respective closing tags.
So let's start with the following regular expression:
/<caption>|<col>|<colgroup>|<table>|<tbody>|<tfoot>|<thead>|<td>|<th>|<tr>|<\/caption>|<\/col>|<\/colgroup>|<\/table>|<\/tbody>|<\/tfoot>|<\/thead>|<\/td>|<\/th>|<\/tr>/
Rather long, isn't it?
We can cut this more or less in half because of the ?
character, which says that the preceding character may appear once or not at all. Using this with \/
(which is treated as a single character) allows the regex to tell the browser that the forward slash is optional.
/<\/?caption>|<\/?col>|<\/?colgroup>|<\/?table>|<\/?tbody>|<\/?tfoot>|<\/?thead>|<\/?td>|<\/?th>|<\/?tr>/
Note that the first part of the regex (<\/?
) and the last character (>
) are uniform throughout. Now to choose between tag names. Below I made a regex that chooses just between those names:
/caption|col|colgroup|table|tbody|tfoot|thead|td|th|tr/
That can go into a subpattern and thus be used in the larger regex:
/<\/?(caption|col|colgroup|table|tbody|tfoot|thead|td|th|tr)>/
A note: The outer parentheses are very important in subpatterns. If they're not there, the regex will match any of the following:
- <caption
- </caption
- col
- colgroup
- table
- tbody
- tfoot
- thead
- td
- th
- tr>
We're trying to match tags here, and this regex will not do the job. That's why subpatterns need parentheses around them: they group various options together.
We can shorten this further though, because of one simple fact: Subpatterns—which are regexes in their own right—can have subpatterns of their own. Three tag names start with c
, while the rest start with t
, which means the regex can be further condensed:
/c(aption|ol|olgroup)/
/t(able|body|foot|head|d|h|r)/
Since two of the c
choices also have ol
as their second and third letters and three of the t
choices are single characters, we can condense them further: the first by making group
an optional subpattern, the second by using a character group.
/c(aption|ol(group)?)/
/t(able|body|foot|head|[dhr])
Below is the complete regex:
/<\/?(c(aption|ol(group)?)|t(able|body|foot|head|[dhr]))>/
Does this look like hairy hocus pocus? It is. And it doesn't even get into the fact that col is an empty element and thus has no end tag! To deal with that, you'd have to separate the possibility of <col>
from all other tag possibilities (the other elements all have end tags), and make that choice a subpattern on its own. If you don't and leave out the new pair of parentheses, you'll get a false negative on most of the intended matches, as the regex will try to match <col
and then the rest of the expression.
I will present the regular expression twice: the first spaced out and indented according the subpatterns in the regex, the second is the regex on a single line. The first is for clarity; a regex written that way will not work (you get an unterminated regular expression literal
error. I checked); the second is how you should write it.
/<(
col
|
(
\/?
(
c
(
aption
|
olgroup
)
|
t
(
able
|
body
|
foot
|
head
|
[dhr]
)
)
)
)>/
/<(col|(\/?(c(aption|olgroup)|t(able|body|foot|head|[dhr]))))>/
Of course, this still doesn't touch the possibility of attributes—but, hey, good enough for now. Let's pick this whole thing apart and have a look at what it all means.
- /<(col|(\/?(c(aption|olgroup)|t(able|body|foot|head|[dhr]))))>/
- This regular expression matches any of the following substrings:
<caption>
</caption>
<colgroup>
</colgroup>
<table>
</table>
<tbody>
</tbody>
<tfoot>
</tfoot>
<thead>
</thead>
<td>
</td>
<th>
</th>
<tr>
</tr>
<col>
- /
- Begins the regex
- <
- The first character must be
<
- (col|(\/?(c(aption|olgroup)|t(able|body|foot|head|[dhr]))))
-
Subpattern: This matches the following substrings:
col
caption
/caption
colgroup
/colgroup
table
/table
tbody
/tbody
tfoot
/tfoot
thead
/thead
td
/td
th
/th
tr
/tr
- col
- Subpattern: This matches the substring
col
.
- |
- An alternate subpattern follows
- (\/?(c(aption|olgroup)|t(able|body|foot|head|[dhr])))
- Alternate Subpattern: This matches the following substrings:
caption
/caption
colgroup
/colgroup
table
/table
tbody
/tbody
tfoot
/tfoot
thead
/thead
td
/td
th
/th
tr
/tr
- \/?
- Optional Character: The first character in this subpattern is an optional forward slash. The escape character (
\
) tells the browser that the next character (a forward slash, /
) is to be treated differently than normal—in this case, as a literal forward slash. The question mark (?
) means that the preceding character (the forward slash, in this case) may appear either once or not at all.
- (c(aption|olgroup)|t(able|body|foot|head|[dhr]))
-
Subpattern: This matches the following substrings:
caption
colgroup
table
tbody
tfoot
thead
td
th
tr
- c(aption|olgroup)
-
Subpattern: This matches the following substrings:
- c
- The first character in this subpattern is
c
- (aption|olgroup)
-
Subpattern: This matches the following substrings:
- aption
- This will match the substring
aption
- |
- An alternate subpattern follows
- olgroup
- Alternate Subpattern: This will match the substring
olgroup
- |
- An alternate subpattern follows
- t(able|body|foot|head|[dhr])
-
Alternate Subpattern: This matches the following substrings:
table
tbody
tfoot
thead
td
th
tr
- t
- The first character in this subpattern is
t
- (able|body|foot|head|[dhr])
-
Subpattern: This matches the following substrings:
able
body
foot
head
d
h
r
- able
- This will match the substring
able
- |
- An alternate subpattern follows
- body
- Alternate Subpattern: This will match the substring
body
- |
- An alternate subpattern follows
- foot
- Alternate Subpattern: This will match the substring
foot
- |
- An alternate subpattern follows
- head
- Alternate Subpattern: This will match the substring
head
- |
- An alternate subpattern follows
- [dhr]
- Alternate Subpattern: This will match one of the following characters:
d
, h
, or r
.
- >
- The last character must be
>
- /
- Ends the regex
I hope you were able to follow all that...
Repetition In Regular Expressions
Sometimes, a character or subpattern must be repeated a certain number of times. Regular expressions allow for that through something called a quantifier. A quantifier looks like this:
In the above examples, the variable num stands for the number of repetitions required, min stands for the minimum number of repetitions required and max stands for the maximum number of repetitions. The difference is, the quantifier using num will match neither more nor less than the number represented by num, while the quantifier using min and max will match anything within the range set by min and max.
Let me demonstrate the first type by rewriting the telephone number regex used earlier in this chapter. As you may recall, it was 1-[2-9][0-9][0-9]-[2-9][0-9][0-9]-[0-9][0-9][0-9][0-9]. Note that, several times, the character range [0-9]
is repeated. This is where the quantifier comes in handy. Using that with this regex, you can rewrite the expression thus: 1-[2-9][0-9]{2}-[2-9][0-9]{2}-[0-9]{4}. If you want to match only long-distance telephone numbers (which include the 1
, then you can shorten this regex even further by using a subpattern and repeating that: 1-([2-9][0-9]{2}-){2}[0-9]{4}.
In Canada, short-distance telephone numbers, do not use the 1
, and consist of either 10 or 7 digits (depending on if the 3-digit area code is dialed). Using a quantifier with a range, we can create a regex to match that: ([2-9][0-9]{2}-){1,2}[0-9]{4}. The quantifier ({1,2}
) says that, in this case, the pattern [2-9][0-9]{2}-
must be repeated from one to two times for the string to match.
Just a note here: if the pattern [2-9][0-9]{2}-
repeats three times, you'll get a match—the expression will simply see the last one or two repetitions to be a matching sequence. Getting around this will take extra coding—most likely the coding I introduce in Decisions.
Flags In Regular Expressions
Flags alter how a regular expression works by making it match more than one character, making it case-insensitive, or other such effects. These go after the regex.
- i
- Case insensitive. For example
/Expression/i would match EXPRESSION
, expression
, eXPRESSION
, Expression
, and so on.
- g
- Global. Matches all occurances of a pattern, not just the first.
I use the global flag quite often to compensate for the different ways browsers handle new lines (explained in Text):
block_of_text = block_of_text.replace(/\r\n/g,"\n")
In this regex, \r\n
refers to the Carriage Return/New Line
type of newline (used by some browsers), and the flag g
(which is in bold and underlined) means to make a global change. Therefore, this script changes all such newlines into the simple \n
character that other browsers use--making the string of text uniform across browsers and thus easier to script for.
One last note: flags stack. In other words, it is perfectly acceptable to have the regex /Regular Expression/gi.
There are several other resources that explain regexes, but I think this covers enough to make them understandable.