The Basics Of Markup
Now that you have an idea what (X)HTML is for, let's get started on how the code actually works.
Standard Generalized Markup Language (or SGML) is a language for creating markup languages, two of which are HTML and XHTML. Since many other markup languages (you can find a list of them in the back of the book) are also based on SGML, what is taught in this chapter will serve you well in figuring out these other markup languages.
Couple of notes here. First. any word in bold that I did not mention earlier I will define shortly, so bear with me a bit. Second: I'm afraid this is all abstract; nothing in this chapter really does anything. That's for later. :-)
Elements
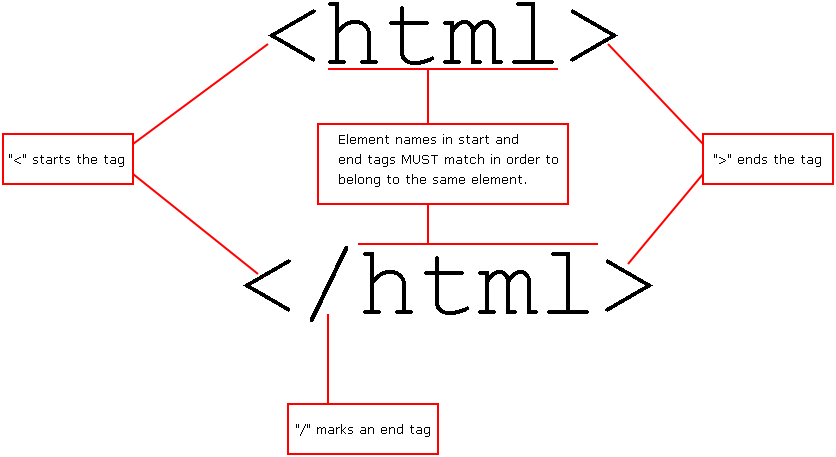
An element consists of—in order—its start tag, its content, and its end tag. To compare it to a book, the start tag is the front cover, the content is the pages, the end tag is the back cover, and the book as a whole is the element.
Content can be just about anything. Most often it is displayed as text, although elements can have other content as well. Below is an example of what I'm talking about: The content is in green bold, the tags are in blue italics, and the element itself is underlined:
<element>This is an example of an element, with tags in italics, content in bold, and the element itself underlined.</element>
Nesting Elements
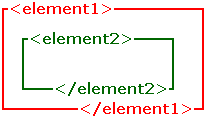
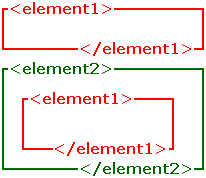
Most elements can contain other elements; putting one element inside another is known as nesting. A good illustration is setting a box inside a larger box (disregarding height for simplicity's sake). Like boxes, one element must fit completely inside another—that is, the inside element must end before the outside element ends. The following examples are correct:
<element1>
<element2>
</element2>
</element1>
The result can be illustrated something like this:
<element2>
<element1>
</element1>
</element2>
Again, an illustration:
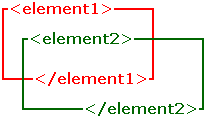
The following example is incorrect.
<element1>
<element2>
</element1>
</element2>
Notice that element2 is partially inside and partially outside element1. Below is an illustration of a possible result:
Going back to the box analogy, if you have two boxes so nested
, you're doing it wrong (and if you've managed to do this without sawing cardboard, you've pulled off a really neat trick). Notice that I said a possible result
; such nesting forces the browser to guess at what you want, and if browsers guess, at least one is going to guess incorrectly.
Also, if you do this in an XML document (for example, an XHTML document) the browser won't even try to guess what you want; it will simply display an error message citing mismatched start and end tags.
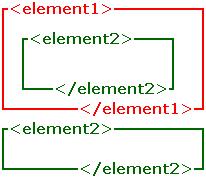
If you want element2 both inside and outside element1 or vice versa, you'll need two separate instances of element1 or element2, as displayed in the following examples of correct nesting shown above.
<element1>
<element2>
</element2>
</element1>
<element2>
</element2>
<element1>
</element1>
<element2>
<element1>
</element1>
</element2>
Yes, it is quite acceptable to have two or more instances of the same element in a markup document. Exceptions to this rule depend on the markup language and are usually uncommon (for example, there are only five single-use elements in (X)HTML).
Element Ancestry
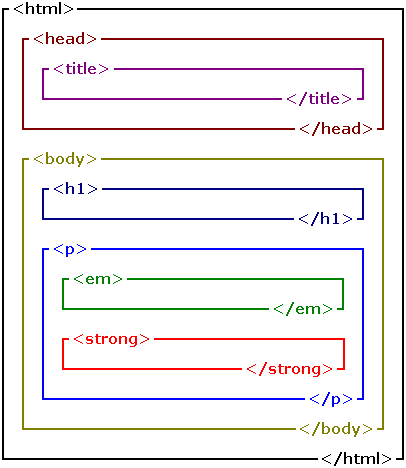
Which element is nested in which is known as element ancestry. To demonstrate ancestry, below is a group of common (X)HTML elements.
<html>
<head>
<title>
</title>
</head>
<body>
<h1>
</h1>
<p>
<em>
</em>
<strong>
</strong>
</p>
</body>
</html>
Below is a diagram of the way they're nested:
There are 6 terms dealing with element ancestry:
- Ancestor
- An ancestor element is an element with one or more elements nested within.
- Descendant
- A descendant element is an element that is nested within one or more elements.
- Parent
- All ancestor elements are parent elements and all parent elements are ancestor elements; the only difference is
parent element
is a more specific term: An element's parent element is the one in which it is immediately nested.
- Child
- All descendant elements are child elements and all child elements are descendant elements; the only difference is
child element
is a more specific term: an element's child element is one that is immediately nested within it.
- Sibling
- Sibling elements are elements that have the same parent element.
- Root
- The root element is the ancestor of all other elements. A markup document may have only one root element; therefore it can have no siblings and (of course) no ancestors.
If the last five terms terms sound like terms used in a family tree, that is the analogy on which they were based. To clarify further, below is an explanation of which elements are which.
Root Element
html is the root element of the document.
Ancestor Elements
The following elements are ancestor elements:
html is the root element, and therefore ancestor of all others.head is the ancestor element of:
body is the ancestor element of:
p is the ancestor element of:
If an element has no elements contained within, it is not an ancestor element. In this case, therefore, the following elements are not ancestor elements:
Parent Elements
html is the parent element of:
head is the parent element of:
body is the parent element of:
p is the parent element of:
The following list shows elements that are ancestors, but not parents of other elements.
html is the ancestor, but not parent, element of:
body is the ancestor, but not parent, element of:
To reïterate what I said earlier, a parent element is an ancestor element; therefore all elements that are listed as not being ancestor elements are not parent elements either.
Sibling Elements
The following elements are sibling elements:
head, bodyh1, pem, strong
The following elements have no sibings:
By definition, a root element cannot have siblings (since it cannot have a parent), and the title element is the only child element of the head element.
Child Elements and Descendant Elements
strong and em are child elements of p. They are also descendent elements of:p and h1 are child elements of body. They are also descendant elements of htmltitle is the child element of head. It is also the descendant element of:body and head are child elements and descendant elements of html
Because it is a root element html is not descendant (and thus not child) element.
Document Type Declarations
The Document Type Declaration (Doctype for short) is a piece of text placed at the beginning of a markup document that points the browser to a file containing information about the markup language being used. This file (known as a Document Type Definition, or DTD) contains the language's rules and codes for special characters. These codes are explained in Special Characters.
This is important; (X)HTML is only one of literally thousands of markup languages used on the Internet and one of several that are officially recognized and useable by many browsers. (X)HTML itself has at least half a dozen versions, and if you don't tell the browser precisely which markup language is being used, the browser will try to guess, which is bad.
The Doctype is placed outside the root element; it is no more an element than a notice that a book is written in English is a chapter. However, the Doctype IS a part of the document, just as such a notice would be a part of the book. Like the root element, each markup document gets exactly one Doctype. If you have no Doctype, the browser must guess at the language being used; more than one and the browser will be confused. Doctype also have a special character sequence at their start: While most tags have <
, Doctype use <!
, though they still close with >
. As it is not an element, a Doctype does not use an end tag.
Two excellent examples of Doctypes are the HTML 4.01 Strict Doctype—which you will see often in this book and is the gold standard for HTML coding these days—and the XHTML 1.0 Strict Doctype.
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
Don't worry about how the Doctype works; that's hairy hocus pocus that we don't need to get into. All that's important is what it does: define the markup language being used. Of course, if you really want to know, you can always look at Picking Apart The Doctype
Also, never confuse a Doctype with a DTD. The latter is a Document Type Definition, an online document that lays out the rules for a markup language. It's quite a different beast altogether.
XML Declaration
Documents written using an XML-based language (and this includes those using XHTML) include another declaration, one that goes before even the Doctype. This is known as the XML Declaration. The simplest simply states which version of XML the page is in and which character encoding the document is using. This declaration looks like this:
<?xml version="1.0" encoding="utf-8"?>
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">